前言
从书本上学到的 MySQL 主键知识十分有限,我们只是知道基础的理论。
在一次面试中,面试官提问:主键索引与普通索引有什么区别?
当场懵逼。
为了深入学习 MySQL 记录下此文。
MySQL 主键(Primary Key)
MySQL 中的键即某种约束,键具有索引的作用,通过约束条件可以使得数据更快的被查到。
主键 是基本每张表都会用到的,一般类型为整型(integer、bigInteger)或者无符号整型(unsigned integer)并按照自然数的顺序自增。
主键是唯一的。
主键是一种索引,可以加快查询效率。
这是我们通常理解的主键,那么主键作为索引,又与普通索引有什么不同?为什么表需要主键?
主键的分类
主键的字段名称一般设置为 ID,当这个 ID 与业务无关时,称为逻辑主键(即 ID 没有实际的意义),如果将用户名(name) 字段设置为主键,该字段是业务中会用到的字段,称为业务主键。
由于主键是业务中经常会用到的键,而业务又经常变更,因此不适合将业务字段作为主键,而是设置一个与业务毫无关系的(ID)字段作为主键。
如果将业务字段用来做主键,例如上面的例子中的 name,系统后台需要修改某个用户的 name 字段,意味着主键也跟着变更了。
如果存在以下场景:
用户个人空间的地址为:http://domain.com/:name,:name 是用户名(即数据库中的 name 字段)。
主键一旦变更,某些页面如个人空间也会跟着变更,假如我收藏了某个用户的空间到浏览器:http://domain.com/user/xiaoming,结果因为用户改名为:xiaohong,这个用户的空间地址就变成了:http://domain.com/user/xiaohong,那我收藏的地址就 404 了,除了这方面的原因,由于可以随意修改主键,也就导致你改了主键的值,其他人又改成之前用过的主键,会产生许多问题,如果某个人又将 xiaogang 的名字改成 xiaoming,那我收藏的地址就会变成原名为 xiaogang 的个人空间,业务变得十分混乱。
主键通常是不能变更的值,因此建议设置一个与业务毫无关系的字段作为主键的值,之所以要用整型是因为查询效率比字符串更高、所需空间更小,可以使用自增自动生成唯一的值。
其他类型如字符串作为主键,由于在插入数据时需要生成唯一字符串,同时还需要判断是否已存在该值,故在插入数据的时候效率也会降低。
除了将单个字段设置为主键,也可以将多个字段绑定在一起作为联合主键(也称复合主键)。
主键设计原则:
- 主键的值 应该 无法被修改
- 主键的值 不应该 与业务有关
- 主键的值 建议 使用系统自动生成(如自增整型)
- 建议 使用单个字段作为主键
- 每张表都 建议 设置主键
为什么表需要主键
想一下如果没有主键,需要删改查除某条数据的时候会有多麻烦:“帮我删掉 name 为 xiaohong 的那条数据”,而 name 属性又没有设置唯一键,存在很多条同名数据,到底是删除哪条?
而当我们设置了 ID 作为主键,那我们就可以说:“删除 ID 为 6 的数据”、“帮我把 ID 为 6 的 name 字段改成 xiaohong”。
主键的其中一个作用即指向该行的数据,键具有约束作用,主键约束可以令数据具有唯一性,设置身份证为主键,那么这个主键就决定了一个人的个人资料,从千千万万个人当中,可以用身份证来指代唯一的一个人。
此外,主键索引可以提升查询效率,将一个字段设置为主键时,便会创建主键索引。
(下文介绍主键索引与普通索引区别)
MySQL 主键与唯一键(Unique Key)的区别
主键字段的值是唯一的,唯一键也要求字段值唯一,这两者的区别在于唯一键的值可以为 NULL,并且可以存在重复的 NULL 数据。
梳理如下:
唯一键的值 可以为空,且不能存在除空值以外重复的值。
主键的值必须 不为空 且不存在重复。
每张表中 只能 存在一个主键,可以存在 多个 唯一键。
从存在意义上来说,主键的作用是指代这一行的数据(如身份证代表一个人),而唯一键只是一种约束作用,用来约束这个字段在这张表不能存在相同值(如限制用户手机号码只能注册一个账号)。
主键索引与普通索引(Normal Index)的区别
扩展阅读:MySQL索引背后的数据结构及算法原理
普通索引的作用只是加快查询效率,并且可以存在重复的值,而主键索引的值是唯一的,它也可以提高查询效率,普通索引的值可以为 NULL,查询一个存在 NULL 的普通索引会导致查询效率提升的作用失效,当一个列设置了索引,同时也应当将其设置为 NOT NULL。
主键索引与普通索引的结构也不同。
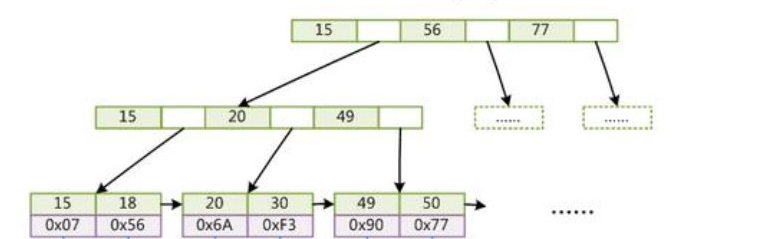
聚簇索引和非聚簇索引(二级索引)
- 聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据
- 非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行
Innodb 存储引擎中,数据表 table 由 table.frm、table.idb 组成。table.frm 保存表结构的定义,table.idb 保存的是数据和索引,这样的结构称为聚簇索引。
Myisam 存储引擎中,数据表 table 由 table.frm、table.myi、table.myd 组成。table.frm 保存表结构的定义,table.myi 保存索引,table.myd 保存数据。在用到索引时,先到 table.myi(索引树)中进行查找,取到数据所在 table.myd 的行位置,拿到数据。所以 Myisam 引擎的索引文件和数据文件是独立分开的,称之为非聚簇索引。
聚簇索引是按照数据存放的物理位置为顺序的,聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索更快。
在 Innodb 中,主键索引是聚簇索引,如果没有主键,则挑选一个唯一键建立聚簇索引,如果没有唯一键,则隐式的生成一个键来建立聚簇索引。
在表结构中只存在一个聚簇索引(主键索引),除此之外都是非聚簇索引(普通索引)。
覆盖索引
一种特殊情况可以不通过聚簇索引查询数据,那就是通过创建联合索引(多个字段作为索引),如果查询的数据在索引中可以直接获取到,那就不需要再到数据行进行查询了。
例如创建索引:idx_name_email
name 字段 和 email 字段是联合索引,当我们使用如下语句查询时:
1 | select name where email = "xxx@idce.com" |
通过 email 来查询 name,由于它们是一组联合索引,因此可以直接从索引中拿到对应的数据。
覆盖索引查询数据只需要从索引中获得,而不需要到数据表中获取,因此可以极大的提高查询效率。
之所以能够从索引中得到数据,是因为索引的结构中保存了对应字段的值。
容易混淆的一个地方:上面介绍的聚簇索引才能保存数据,那为什么普通索引也能保存数据?
其实这里指的是表的数据,通过聚簇索引找到的数据是直接找到表对应行的一整行数据,而索引保存的数据是这个字段的值,因此可以通过索引得到对应字段的值。
面试官曾经问我的问题:索引会保存字段的值吗?
当时觉得不会,应该是保存对应行的所在地址才对。但其实是会保存的,因为只有保存了这个数据,查询索引字段才能快速进行数据对比从而筛选数据,如果能不回到表查询,则不回到表查询,回到表查询的效率比直接从索引拿数据低得多。
索引的结构,一侧是字段的值,另一侧是下一个数据的地址: