
前言
不论书上还是网上的技术论坛分享的 MySQL 查询优化方面的文章都不推荐使用 SELECT *,但是他们从未说过为什么不能这样用或者仅仅只是浅显的描述原因,但并不能让人觉得心服口服,那么——到底在 MySQL 为什么不用 SELECT * 来查询呢?
老娘很好奇!——「千反田」

使用场景
实际上我标题党了!标题其实是一个伪命题。
抛开使用场景就提出命题全部都是无稽之谈!
比如一个 MySQL 的表 users 如下:
| name | 类型 | 备注 |
|---|---|---|
| id | int | 自增主键 |
| name | varchar | 用户昵称 |
| varchar | 注册邮箱 |
现在需求是:产品需要查询全部的用户资料然后导出 Excel。
当然,我们肯定直接用 SELECT * FROM users 查询了。
你也可以用下面的方法:
1 | SELECT id,name,email FROM users; |
这两种方法是等价的,*(星号)的本质就是查询所有字段,并不是说使用星号就跟列出所有字段有什么不同的地方。
上述场景,两种方法的结果和过程完全一致。
SELECT * 的优点
看到这里是不是颠覆常规的认知了?
众所周知,不论书上还是网上一致抵制 SELECT 星号查询。
为什么还能有优点呢?
抛开使用场景不谈而直接讨论命题的做法显然不可取。
以技术的角度来讨论这个问题,把不需要的字段查出来确实不好,为什么不好我们下文再介绍。
如果以项目经理的角度来说,SELECT 星号查询能大幅提升开发效率和减轻后续维护的时间。
这就涉及到「性能和开发效率的抉择」两者无法兼得。
为了提高查询效率,我们使用了 SELECT 字段1,字段2,字段3 进行查询,但如果后期我们修改表结构,表中新增了一个字段 4,那开发人员就得找到查询语句再补充一个字段 4,如果数据库模型使用了诸如 Laravel 的 fillable (可填充字段),你不仅要修改查询语句,还得修改模型。
示例:
1 | <?php |
虽然这个 fillable 跟查询没有关系,但是不设置 fillable 在插入数据字段就会屏蔽
业务更新后,users 表新增了一个 address (住址)字段,业务需求不仅要显示出 name 和 email 现在还要把住址也显示出来。
于是,代码修改:
1 | <?php |
是不是很麻烦?因为添加一个新字段要修改两个地方的代码,开发效率大大降低了。
相反,如果直接使用星号查询呢?
Laravel 的 Model 中,与 fillable 相反的是 guarded(不可填充字段),将 guarded 的值设置为空数组代表所有字段(*)都可以填充(fillable)。
代码修改如下:
1 | <?php |
guarded 也跟查询没有关系,它指代的是需要屏蔽哪些字段,与 fillable 相反
现在即使添加了新的 address 字段,我们也不需要回去修改代码了。
所以,SELECT 星号的优点就是可以提高开发效率,而且这种开发效率的提升是极为显著的,试想一下如果一张表后期改了很多字段,不仅有新增字段还有删除的字段,如果使用 SELECT 字段1,字段2 的方法来查询,每次表结构更改就得重新审核一遍所有该表的查询语句,因为一旦忘记修改某处那就会报字段不存在的错误。
事情往往都有两面性,尽管 SELECT 星号查询会在一定程度上降低性能,但它却能提升开发效率,我们应该根据使用场景来决定具体用哪种方法,在需要高度优化的场景,我们自然不会使用低性能的 SELECT 星号,规则是死的,人是活的,场景不断变化,我们的查询语句也要跟随变化。
缺点
上文提到使用 SELECT 星号查询会影响性能,这其实是一句很含糊的话,到底是什么性能?性能只是一种笼统的概念,网上大都没有深究具体哪些地方会受到影响,无非都是说查询的字段越多查询速度越慢,诸如此类。
老娘很好奇!!——「千反田」

接下来就来详细的探讨 SELECT 星号影响的到底是哪些性能。
磁盘 IO
我们知道 MySQL 的本质是存储在磁盘上的文件,因此查询操作就是一种读取文件的行为。
(当然还有一种是不需要读取文件的,后文介绍)
如果查询的字段越多,说明要读取的内容也就越多,因此会增大磁盘 IO 开销。
在对于 TEXT、MEDIUMTEXT 等更大长度的字段时,效果尤为明显。
内存
后端代码查询 MySQL 后将查询结果保存在变量中,变量会占用内存资源,字段越多变量占用的内存就越高,看下面的例子,展示了两种不同查询占用的内存情况。
1 | # 查询语句 |
如果只查询部分字段:
1 | # 查询语句 |
只查一个字段和查出全部字段内存占用差距非常大,尤其是在有 text 或者较大长度字段时,千万不要使用 SELECT 星号把无关的字段也包含到查询语句中,因为查找这些字段不仅没有意义还会徒增内存消耗。
网络传输 / 带宽
我们知道 MySQL 可以部署在与项目相同的服务器,也可以不在同一台服务器,当项目与 MySQL 不在同一台服务器时这种情况就会更加严重。
同理,如果使用了 TEXT 等大字段,要传输的内容也会变得更多。
从另一台部署了 MySQL 的服务器进行查询时,另一台服务器需要把数据传输给当前服务器,这中间是通过网络进行通信的,查询的数据越多返回的数据量也就越大。
数据传输量越大占用的网络资源就越多,这也是为什么前端要把 js 文件压缩成 min 减小体积的原因,只要传输的文件内容体积变小,传输花费的时间就越少,而大文件直到传输完成前网络连接不会断开,如果连接数一直增加最终可能超过服务器的承受能力导致后续连接直接未响应。
如果 MySQL 服务器是单独的,那么前面提到的缺点还会成倍的增加。
试想一下,MySQL 服务器中读取了多余字段(磁盘 IO / 网络等性能消耗),然后再把数据传给项目所在服务器(多余字段导致内存增加),也就是说两台服务器都徒增压力。
无法高效利用索引
在本博客前一篇文章中提到对 MySQL 占用内存过高的优化技巧。
因为 MySQL 为了查询优化占缓存了许多数据到内存中,而如果我们能利用内存的数据,查询效率能得到质的飞跃。
其中之一就是索引。
MySQL 中存在一种概念叫做「覆盖查询」,当查询的字段全部都是索引时,这时 MySQL 可以直接从索引中返回数据而不需要再次去查询表。
示例,orders 表中存在索引字段:user_id 和 goods_id,直接查询这两个字段时,通过 explain 分析可以发现:
1 | explain select user_id,goods_id from orders where user_id = 1 limit 10; |
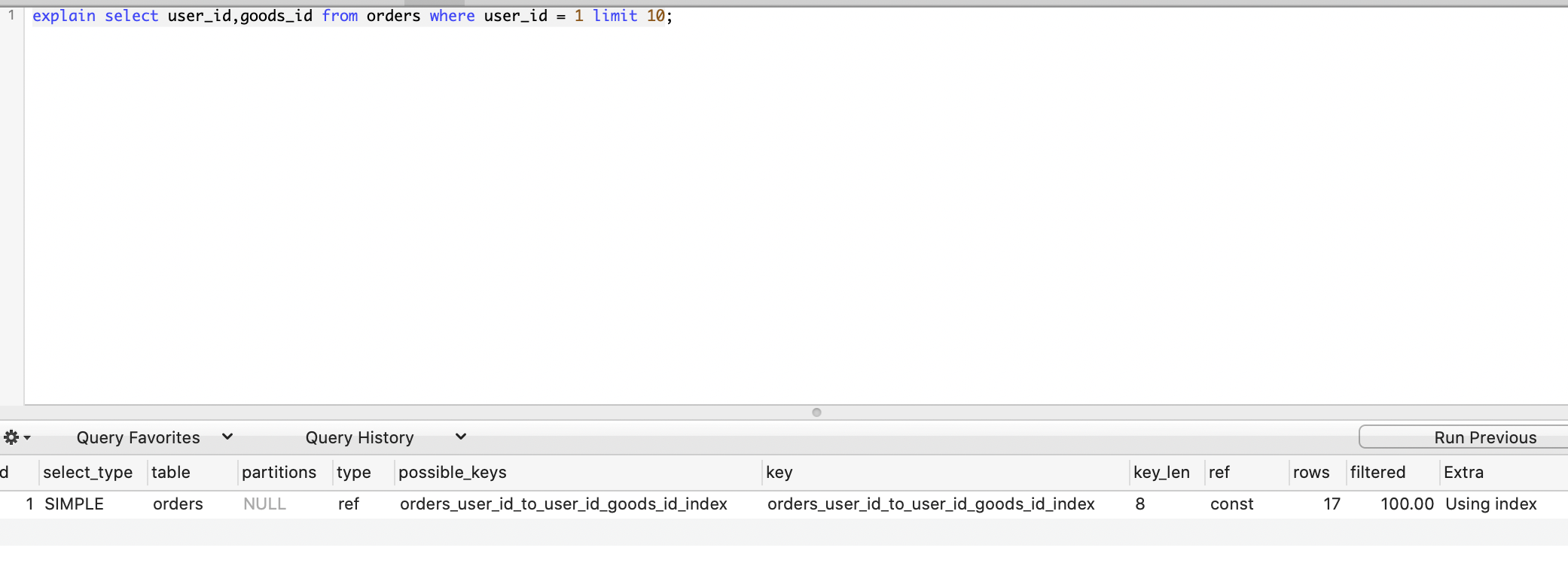
Extra 字段返回的结果是:Using index
这里说明查询结果用到了索引,「覆盖查询」的原理就是在 MySQL 创建表数据的时候,会对索引的数据创建单独的结构(注意:索引里面就包含了数据),因此查询索引字段直接从这个单独的结构里面就能拿到数据了,就不需要通过索引去定位行再从行中取记录。
如果我们把上述的查询语句修改一下,加入一个非索引字段 price:
1 | explain select user_id,goods_id,price from orders where user_id = 1 limit 10; |
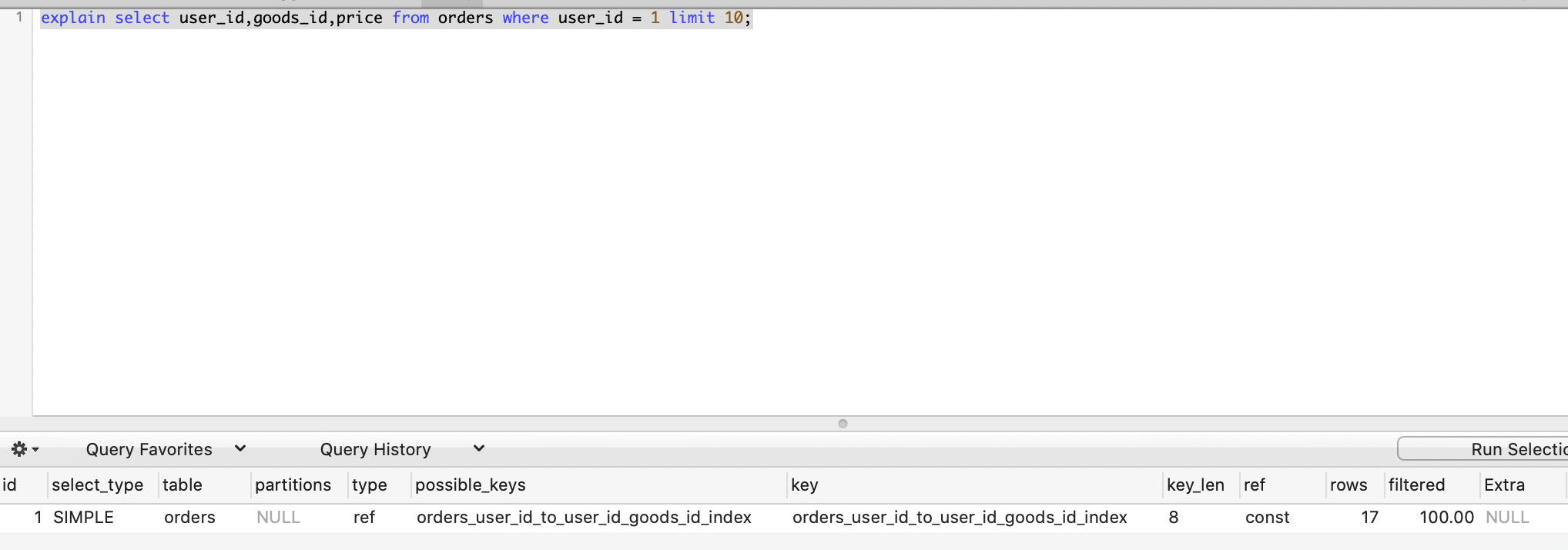
可以发现,Extra 原本的 Using index 已经变成 NULL 了。
这是因为 price 不是索引字段,因此 MySQL 无法直接得到数据,必须定位到行才能拿到 price 字段,这种通过索引定位行再回到表中查询的过程叫做「回表查询」。
「覆盖查询」是从索引直接拿到数据,不需要「回表查询」,因而查询速度更快。
通过上面的分析,我们知道要实现「覆盖查询」的条件必须是:查询的字段全部都是索引。
显然我们不可能给每一张表的所有字段都加上索引,因此使用 SELECT 星号在字段比较多的表中无法实现「覆盖查询」。
尾语
保持一颗「千反田的好奇心」,相信技术一定会有很大突破。
