
前言
今天在做一个网页项目的时候,无意中发现一篇文章在访问的时候会请求两次。
这个问题其实很难被发现,因为前端几乎看不出来,如果不看 Network 的记录根本不知道请求了两次。
发现这个问题也是偶然,我在测试文章 ID 的加密,然后在控制台打印加密的结果。
突然发现刷新一次页面居然会打印出两个结果,类似下面这样: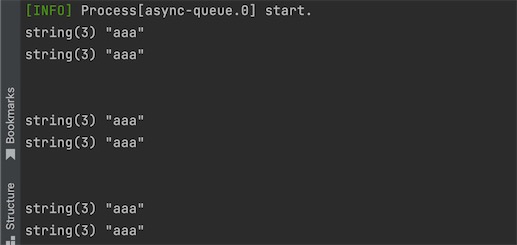
一开始我以为是后端代码的问题,结果找了个遍也没发现什么问题。
接着我看了下网络请求,发现确实是请求了两次,可以肯定不是后端的问题了:

排查工作
出现请求两次的情况一般是 META 标签有可能有什么预加载的指令,
或者 JavaScript 脚本刷新了页面,又或者 Ajax 发送的试探性 HEAD 请求。
排查的方法其实很简单,就是一段代码一段代码的删掉。
首先把奇怪的 META 标签全部删掉,发现没有解决;
接着把所有的 JS 脚本全部删掉,发现还是没有解决;
这样就很奇怪了,能够引起页面重新加载的因素都被排除了,那还有什么我不知道的原因?
所有的可能性
现在页面删的只剩下 HTMl 代码了,总不可能是 HTML 代码的问题吧?
虽然感觉自己很傻,但还是尝试删除 HTML 代码。
一段一段的删除 HTML 代码,删一段就测试一遍。
结果最后……居然还真是 HTML 代码的问题。
福尔摩斯说过:“排除了一切不可能之后,剩下的即使多么难以置信那都是真相”。
原来 HTML 代码也会导致页面重新加载,这就属于我的知识盲区了。
分析请求头
把两次访问记录的请求头扒下来,关键部分如下:
1 | GET /res/239243 HTTP/1.1 |
第二个请求:
1 | GET /res/239243 HTTP/1.1 |
分析上面两个请求头,可以得到很多有用的信息。
我们可以从 Referer(来源页)判断第一次请求是从后台地址:/admin/resources/index 直接打开文章链接的,
而第二次 Referer 却是当前文章的链接:/res/239243。
所以我们可以确定从后台打开文章的时候,又发起了一次请求。
接着再看 Accept 字段,这是当前请求可以接受的返回资源类型。
第一个 Accept 第一个是:text/html,即接收 HTML 文档。
而第二个 Accept 却是接收 image 类型为主的资源数据。
通过上面的分析,我们可以得到两个线索:
- 第一次请求是从后台来的,第二次请求是从当前页面来的
- 第二次请求的是图片类型的资源
通过上面两点可以猜出是文章页面的某个图片多发出一次请求。
最开始我以为是图片懒加载的原因,但是删掉所有 JS 代码都没有解决。
找出原因
一段段删除代码测试之后,发现下面这段问题代码:
1 | <div class="navbar-brand"> |
这到底有什么问题?根本就看不出来。
语法上完全没错,也没有 JavaScript(如懒加载等)。
哪怕把所有的 css 样式全部去掉,a 标签也去掉,改成下面这样:
1 | <div><img src="#"></div> |
这么简单的一段 HTML 代码都会导致页面重新加载两次。
img 标签的 src 属性是图片的地址,这个地址是后台可以动态改变的:
因为还没设计好网页的 LOGO,所以我临时用井号作为占位符。
问题就出在这个 img 标签上,而且非常匪夷所思。
IMG 标签的坑
IMG 标签在 src 属性为空或者无法正常读取图片地址的时候,某些浏览器就会认为这是一个缺省值,然后以当前页面当做图片的路径进行加载,这就是为什么会导致网页加载两次的原因了。
同类型的 HTMl 标签还有 form,即使你不配置提交的地址,它也会默认提交到当前页面。
1 | <form> |
上面的代码等同于在当前页面提交表单。
当不填写 action 属性,浏览器就会自动配置一个缺省值,也就是当前地址。
避免请求两次
不同的浏览器的处理结果也会不一样,比如火狐和谷歌,对于 img 标签的 src 默认值处理方式可能不同。
假设一个图片的链接是动态的,那么最好是不要像下面这样:
1 | <img src="" /> |
而应该写成如下方式:
1 | <img> |
这样就可以避免因为图片的地址缺省值导致页面加载两次了。